Abstract
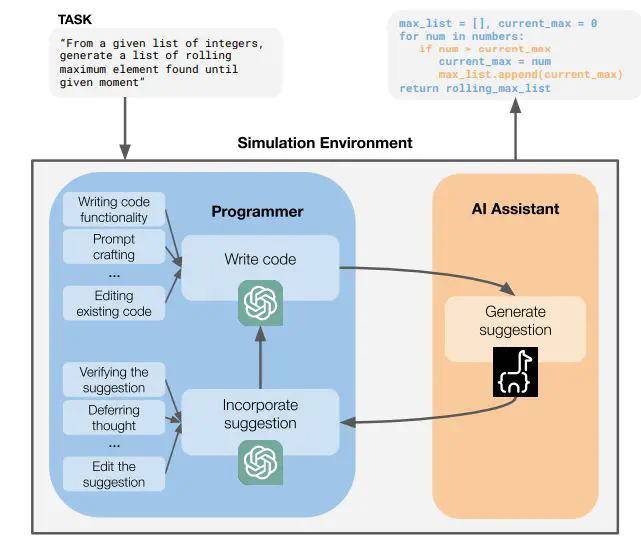
Large language models (LLMs) are increasingly used to support humans in tasks involving writing natural language and programming. How do we evaluate the benefits of LLM assistance for humans and learn from human interaction? We argue that benchmarks that evaluate the abilities of the model in isolation are not sufficient to reveal its impact on humans. Ideally, we can conduct user studies where humans complete tasks with the LLM and measure outcomes of interest. However, this can be prohibitively expensive in terms of human resources, especially as we want to iterate on model design continuously. We propose building a simulation environment that mimics how humans interact with the LLM, focusing in this work on assistants that provide inline suggestions for coding tasks. The environment simulates the multi-turn interactions that occur in programming with LLMs and uses a secondary LLM to simulate the human. We design the environment based on work that studies programmer behavior when coding with LLMs to make sure it is realistic. The environment allows us to evaluate the abilities of different scales of LLMs in terms of simulation metrics of success. The simulation also allows us to collect data that can be potentially used to improve the LLM’s ability to assist humans, which we showcase with a simple experiment.